Jopara Vibe
Real language, captured as it is spoken.
Guaraní and Jopará are complex, dynamic, and alive. We treat them as such.
Current focus: Guaraní and Jopará
Guaraní and Jopará are not standardized systems.
They are shaped by region, context, and daily use.
What is spoken is not always what is written.
What is written is often not how people actually speak.
Most digital systems are not built for this kind of language.
They assume consistency, structure, and standardization.
Our work focuses on capturing real speech — in its variation, its inconsistency, and its context.
Not as a simplified version. But as it actually exists.
Why this matters
Language does not disappear. But it can become invisible in the systems that shape everyday life.
Most digital environments are built around a limited set of languages.
When language is not represented, it is not recognized.
When it is not recognized, it is not supported.
This affects how people interact with technology, what they can access, and how their language is carried forward.
Language is not just communication. It is context, identity, and continuity.
System
A structured linguistic dataset forms the foundation. Controlled recording environments ensure acoustic quality. The app refines the dataset through real-world input over time.
Foundation
A structured linguistic dataset forms the foundation.
Relationships, context, and meaning are organized at scale — across phrases, domains, registers, speakers, and validation states.
Controlled
Controlled recording environments ensure consistency and acoustic quality.
Studio conditions provide clarity, control, and reliable source material — the quality layer the rest of the system rests on.
Real-world layer
The app refines the dataset through real-world input.
Everyday speech, structured contributions, and audio capture extend the dataset over time — the app is the refinement layer, not the foundation.
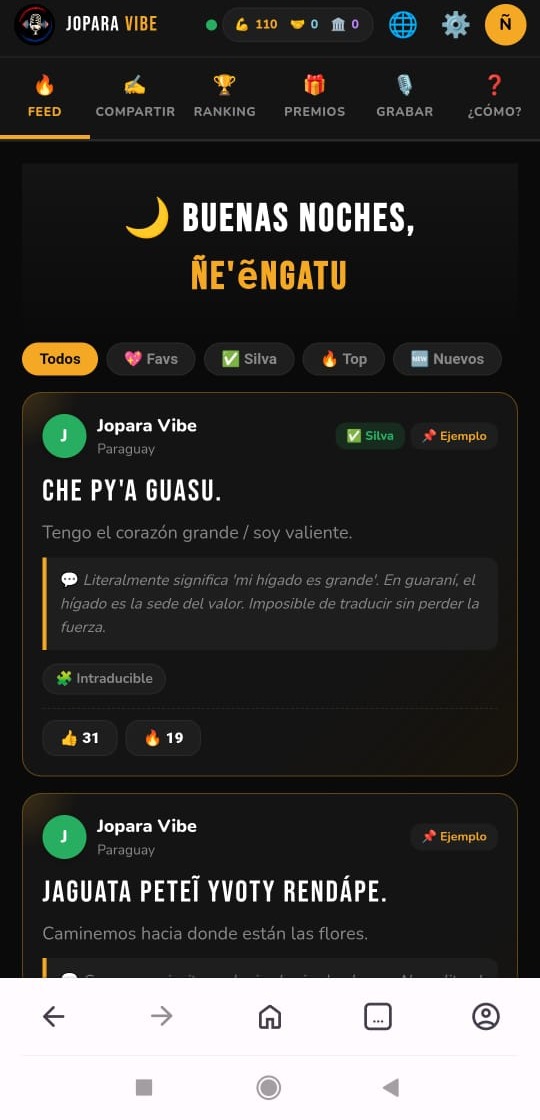
Captured
Real speech, with its meaning intact.
Each phrase arrives with translation and cultural context — preserved in the form it is actually used, not a simplified or standardized version.
Contributed
Structured contribution, not open submission.
Each entry is shaped by fields: phrase, translation, context, category. The structure is what turns everyday language into material the dataset can absorb.
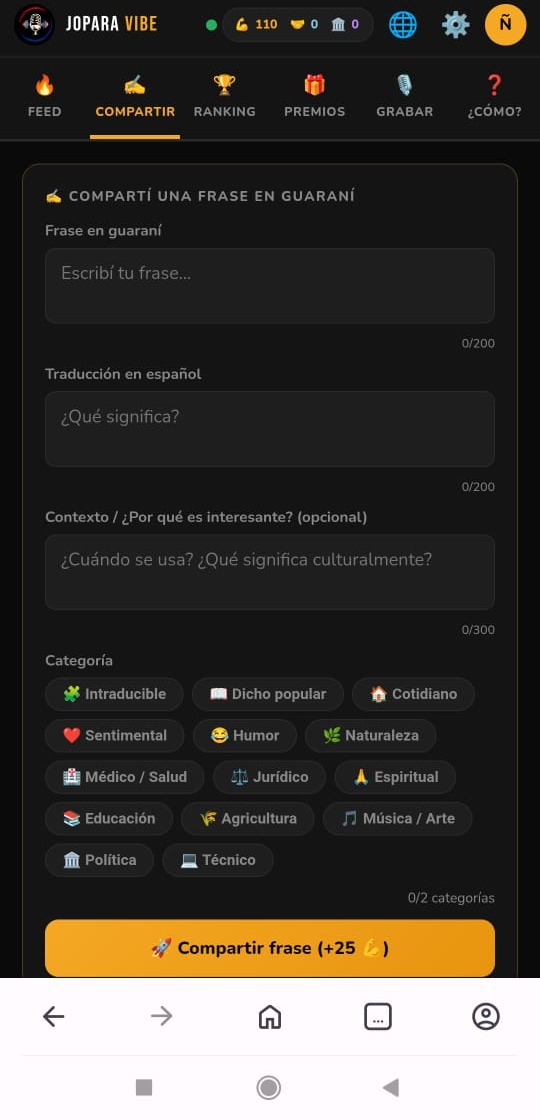

Framed
Built around principles from the language itself.
Mbarete, Pytyvõ, Mbojerovia — strength, mutual help, trust. The system is shaped by values drawn from the culture it serves, not imposed on it from outside.
Extended
Audio capture extends the dataset with acoustic material.
Selected contributors record guided phrase sets. These feed the speech layer that underpins recognition and synthesis over time.
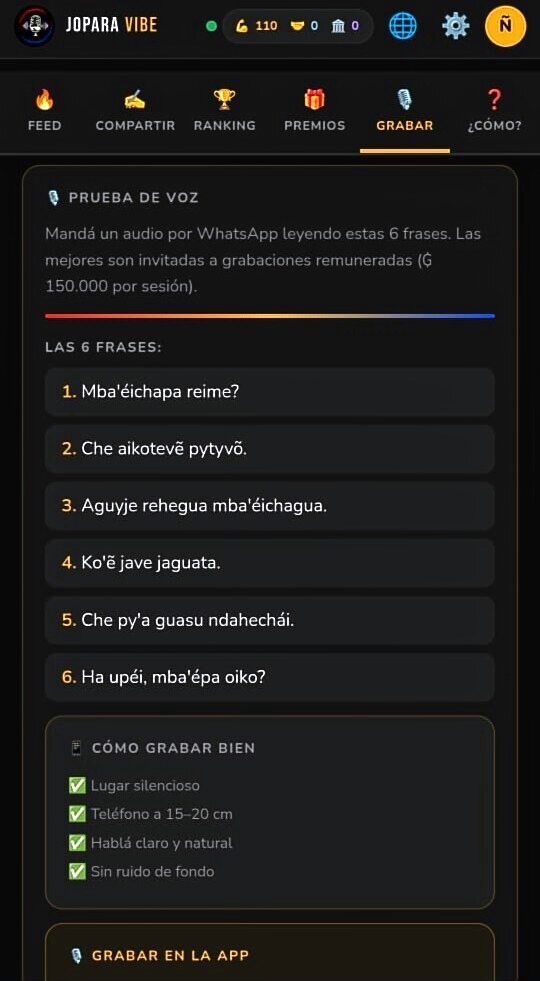
Access
Access to the current system is controlled.
Participation is limited to selected contributors and structured programs.
This ensures consistency, data quality, and a reliable foundation for the systems being developed.
The system is not designed for open, unsupervised input.
It is built through guided collection and controlled environments.
This is where it starts.